
详解robots协议文件的相关问题,主要谈谈robots.txt是什么、配置怎么写、有什么作用;以及,怎么给自己的网站合理配置robots.txt规则。

什么是robots.txt协议?
简单地说,robots协议就是网站空间目录里的一个txt文件。通过在这个文件里添加相应的规则内容,我们可以规定搜索引擎蜘蛛如何爬取网站页面。robots.txt是目前几乎所有主流搜索引擎共同遵守的一项互联网准则,让网站管理者可以掌控自己网站在搜索引擎上的展现。实质上,robots的规则主要就是两种指令:Allow指令(允许抓取)和 Disallow指令(禁止抓取)。
也就是说,robots.txt协议文件其实是给搜索引擎准备的。搜索引擎比如谷歌的蜘蛛来到网站,首先就会检查网站的robots规则,然后根据这些规则的指导进行爬取工作。所以,一般网站都是需要配置合适的robots规则,尤其是网站的某些类目或者页面不想被搜索引擎抓取到。如果网站没有配置robots文件,那就相当于默认全站可抓取。
robots.txt的指令规则
上文已经提到,robots.txt主要指令就是Allow和Disallow这两个。但,要组成一个完整的robots配置,还需要有其他指令的加入。接下来,我们逐一看下robots.txt的指令规则。
User-agent指令
任何指令都要有命令对象,robots规则指令也是如此。可能有人会疑惑:命令的对象不就是搜索引擎爬虫吗?是的,robots.txt就是指导这些爬虫的抓取;但是,全球的搜索引擎这么多,如果有些内容你就想给谷歌抓取,而不想给百度抓取,那怎么办呢?所以,User-agent指令还是必不可少的,通过它我们可以规定robots规则的限定对象。比如,对象限定为谷歌,就可以用:User-agent: Googlebot,Googlebot就是谷歌的爬虫代号,其他主要的搜索引擎爬虫代号还有:
| 搜索引擎 | 蜘蛛代号 |
|---|---|
| 谷歌 | Googlebot |
| 百度 | Baiduspider |
| 360搜索 | 360Spider |
| 搜狗 | Sogou News Spider |
| 必应 | bingbot |
| MSN | msnbot |
一个搜索引擎可能不止有一种蜘蛛,比如谷歌,除了常见的Googlebot外,它还有Googlebot-Image之类的爬虫,专门用于爬取图片等内容。如果你想了解所有搜索引擎的爬虫代号,可以查看这里。
Disallow指令
Disallow指令就是规定网站中哪些内容不想被搜索引擎抓取。举几个例子:
Disallow: /folder/(folder这个网站目录,包括里面所有页面不要抓取)
Disallow: /file.html(不要抓取网站中file.html这个页面)
Disallow: /image.png(不要抓取image.png这个图片)
Allow指令
和Disallow指令的作用相反,Allow指令告诉搜索引擎哪些页面可以被抓取,这个指令一般是配合着Disallow指令发挥作用,毕竟如果没有Disallow,那就已经默认可以抓取了。同样,举个例子:
Disallow: /photos(不允许抓取photos这个目录内容)
Allow: /photos/car.jpg(只有car.jpg这个图片可以抓取)
注意:括号里都是讲解内容,真正使用这些指令规则时,不能加括号。
Crawl-delay指令
这个指令可以规定搜索引擎抓取页面前需要等待一段时间。比如:Crawl-delay: 100,意味着需要等待100毫秒。这个指令一般用不到,而且谷歌不会执行这个指令。
Sitemap指令
Sitemap指令就是告诉搜索引擎网站的Sitemap站点地图在什么位置(一般位于网站根目录中)。比如,我们网站的robots.txt文件就含有sitemap指令,大家可以自行查看:www.yundianseo.com/robots.txt

只有Google,Ask,Bing和Yahoo支持此项指令。
模糊匹配指令
在实际应用中,有时候我们需要制定某类文件或者页面不被谷歌等搜索引擎抓取。这时,就需要应用到模糊匹配指令。robots规则中的匹配指令是两个符号:*和$。符号*前面也有说过,是代表全部的意思;符号$则是用于结尾,代表符合结尾格式的地址。例如:Disallow: /*.gif$,表示不抓取网站中结尾格式为gif的所有文件。
常用的robots.txt配置
|
robots.txt规则 |
功能说明 |
|---|---|
| User-agent: *
Disallow: / |
禁止所有搜索引擎抓取网站任何页面;一般用于网站尚未建设完成时使用,屏蔽搜索引擎抓取。 |
| User-agent: *
Disallow: /abc/ |
禁止所有搜索引擎抓取abc这个目录内容;比如,wordpress网站需要禁止抓取wp-admin这个管理登录的目录。另外,不要使用robots规则限定你的隐私内容,仍然有可能泄露。隐私页面最好还是设置为普通用户不可见最为安全。 |
| User-agent: Googlebot
Allow: / User-agent: * Disallow: / |
只允许谷歌蜘蛛爬取网站,其他搜索引擎禁止爬取。 |
| User-agent: Googlebot
Disallow: / User-agent: * Allow: / |
除了谷歌不可以抓取,其他搜索引擎均可爬取网站。 |
| User-agent: *
Disallow: /abc.html |
禁止所有搜索引擎抓取abc这个html页面;此规则可用于禁止抓取网站中某个页面。 |
| User-agent: *
Disallow: /images/abc.jpg |
禁止所有搜索引擎抓取网站images目录下的abc这个jpg图片。禁止抓取某个页面或者图片等文件,需要正确填写所在位置。 |
| User-agent: Googlebot
Disallow: /*xls$ |
禁止谷歌抓取网站中所有以xls为结尾格式的文件。 |
使用robots.txt的注意事项
- 如果使用robots.txt协议,首先一点就是确保配置正确,不要影响到正常内容的抓取。网站如果长时间没被谷歌收录,有可能就是因为robots.txt配置错误导致的。
- 为了方便搜索引擎查找、识别,robots.txt一般放在网站的根目录中最好,也就是空间最开始的文件目录里。
- robots文件,必须是txt格式结尾,并且全称为robots.txt,不要大些首字母变成Robots.txt或者其他任何形式。
- robots.txt规则主流搜索引擎都会遵守,但不排除有些网站或者软件的爬虫会忽视这个文件,比如一些内容采集软件就不会遵守规则,所以不要指望robots规则可以把这类软件拦截在外。
- 如果有些页面信息是比较私人的或者含有隐私,不要把它添加到robots文件内容中,虽然搜索引擎不会抓取,但访客是可以直接打开robots文件,查看到该页面地址的。
- 如果一个网站有二级域名,那么二级域名的网站也是需要配置robots.txt文件的,如果它含有不想被抓取的内容,主域名配置的robots文件对二级域名不起作用。
- robots.txt最好含有sitemap地址,能够帮助搜索引擎更快地找到网站的站点地图。站点地图利于搜索引擎的抓取和收录,网站如果还没有sitemap,可以参照此篇文章进行创建:Sitemap站点地图生成工具
如何制作robots.txt文件
制作robots.txt文件的方法很简单:在电脑桌面创建一个txt文本,然后命名为robots即可。书写规则内容时,注意:
- 每行一个规则指令,如果是两段规则,中间空一行;
- 使用英文输入法,不要使用中文输入法,: 号后面空一格。
示例:
Disallow: /(第一段)
User-agent: Googlebot
Allow: /(第二段)
如何提交robots.txt给谷歌
网站中已经有了robots.txt文件,可以通过robots测试工具提交给Google,让其尽快识别。打开工具:https://www.google.com/webmasters/tools/robots-testing-tool,选择资源(先得到谷歌站长工具中验证网站所有权):
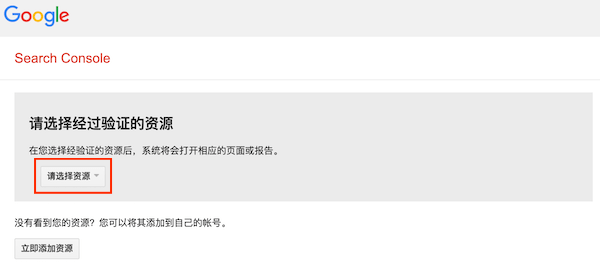
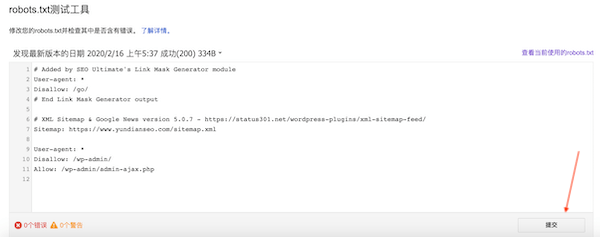
测试无误后,点击提交:
有什么想说的?欢迎评论留言
发表评论
Want to join the discussion?Feel free to contribute!

写的很用心,详细,谢谢
看过全文对robots文件有了清楚的理解,谢谢分享